Main comparison on real data
Table 2 summarizes the test-set performance of all seven models on the real Mendeley benchmark. Figures are mean ± 95% CI across seeds for learned models.
Three findings stand out. First, the tree-ensemble methods (RF and XGBoost) produce the lowest MAE on both overall and approaching-failure subsets, with an inter-estimator gap below 1%: the physics-inspired feature set is the dominant driver of performance, not the specific learner. Second, the \(\sim\)6\(\times\) MAE gap between tree ensembles and heuristic baselines demonstrates that the proposed approach provides substantial value over industry-standard threshold rules; Reviewer-flagged concerns about weak baselines are addressed both by adding XGBoost/LSTM/CNN and by the enlarged gap on real data. Third, deep sequence models (LSTM, 1D-CNN) do not improve on tree ensembles under fair-comparison conditions–consistent with the bimodal censored-regression structure of the TTF target (64% of test samples are censored at the cap). We note that 1D-CNN exhibits substantial seed variance (\(\pm 37\) s), reinforcing the importance of multi-seed evaluation.
Per-class performance
Table 3 decomposes MAE by failure class, restricted to approaching-failure samples where a non-trivial regression target exists.
Three observations follow. First, the near-zero MAE on ECL and no-failure classes for tree ensembles reflects correct identification of the “ceiling” regime: these trajectories never cross threshold in the observation window, and the models correctly predict the cap. Deep models show \(\sim\)30–50 s calibration error on these classes, consistent with softer output activations. Second, the EDFA class is the hardest, with \(\sim\)127 s MAE even for the best models; this reflects the wide variance in EDFA decay rates across the 756 lightpaths (ranging from marginal \(\sim\)3 dB declines to full exponential collapses). Third, the NLI class benefits more from XGBoost than RF, with approaching \(R^2\) rising from 0.08 to 0.14–consistent with boosting’s better handling of accelerating, non-monotonic degradation signatures.
Synthetic-data cross-physics validation
On the synthetic multi-physics benchmark (details in supplementary material), the same Random Forest model achieves 17.9 s MAE with \(R^2 = 0.914\). Cross-model validation (train on one physics, test on another) yields 10–32 s MAE on transfers between gradual modes (OU \(\leftrightarrow\) exponential \(\leftrightarrow\) Weibull \(\leftrightarrow\) oscillatory), and 38–52 s MAE on the step-failure class–which is physically unpredictable from pre-failure telemetry and serves as a control case. These results are consistent with the real-data findings in that gradual degradation modes are learnable and transferable, while catastrophic step changes are not (Figs. 4 and 5).

Failure-detection performance on synthetic multi-physics trajectories. Four representative scenarios (OU drift, exponential decay, Weibull acceleration, step) show OSNR evolution (blue), hard-failure threshold at 15 dB (red dashed), soft-alarm threshold at 18 dB (orange dashed), detection moment (green vertical line) and actual failure moment (red vertical line). Lead times vary by mode: fast exponential 79.6 s, OU drift 47.2 s, Weibull 34.4 s. The step-failure panel illustrates the physical limit: catastrophic failures cannot be predicted from pre-failure telemetry and the method correctly does not attempt to do so.

Lead time distribution across synthetic scenarios (top) and overall (bottom-left), with summary statistics (bottom-right). Gradual failure modes achieve mean lead time 51.8 s, median 49.0 s, range 33–87 s; 60 s operational target shown for reference.
Per-alarm interpretability: case studies
To demonstrate that the framework provides operationally meaningful explanations at decision time, we examine four trajectories drawn from the real-data test set representing the four qualitative outcomes an operator may encounter:
Case 1 – EDFA, true positive (traj 70).: OSNR declines steadily from 19 dB over 800 samples. The alarm fires at \(t{=}724\), 44 s before the 15 dB crossing (Fig. 6). SHAP attribution at the alarm moment identifies current OSNR (−490 SHAP), rolling standard deviation (−85), SNR\(_{t-1}\) (−55), and rolling mean (−45) as the dominant drivers–an operator-readable diagnostic of “current signal is low, recent history is consistently low with little noise, and this is a genuine degradation rather than a measurement transient.”
Case 2 – NLI, true positive (traj 2087).: OSNR declines sharply from 17 dB to 15 dB in 350 samples. The alarm fires at \(t{=}337\), 30 s before failure (Fig. 7). The shorter lead time reflects the accelerating degradation characteristic of NLI. SHAP attribution at alarm follows the same ranking as the EDFA case, indicating that a single decision logic applies across physically distinct failure modes–a property valuable for operator training.
Case 3 – stable link, true negative (traj 1872).: OSNR remains at 19 dB for the full 900 samples. The predicted TTF remains pegged at the 880 s ceiling with small (\(\sim\)30 s) transient dips that never approach the 60 s alarm threshold. This demonstrates that the persistence filter and learned decision boundary combine to produce “trusted silence” on stable links.
Case 4 – false positive (traj 1215).: OSNR declines slowly from 18.8 dB to \(\sim\)15.2 dB over the full trajectory without crossing the 15 dB threshold within the observation window. An alarm fires at \(t{=}894\), six samples before trajectory end (Fig. 8). SHAP attribution reveals that current OSNR and rolling mean drive the decision–reasoning that would likely resolve to a true positive had the observation continued beyond sample 900. This case illustrates the intended use of SHAP in production: operators can examine the explanation, classify marginal alerts, and feed disposition back for continuous learning.

Case study 1 – EDFA true-positive (trajectory 70). Top: OSNR evolution with 15/18 dB reference lines, alarm moment at \(t{=}724\) (green), and actual failure at \(t{=}768\) (red). Middle: Random Forest predicted time-to-failure over the full trajectory, showing smooth descent and crossing of the 60-s alert threshold. Bottom: SHAP value at the alarm moment; negative contributions push predicted TTF down. Current OSNR dominates (\(-490\)), followed by rolling standard deviation, SNR\(_{t-1}\), and rolling mean—an operator-readable pattern of “low current, low recent, low noise.”.

Case study 2 — NLI true-positive (trajectory 2087). Panel layout as in Fig. 6. Alarm at \(t{=}337\), failure at \(t{=}367\), lead time 30 s. Shorter lead reflects NLI’s accelerating dynamics. SHAP ranking at the alarm moment is consistent with the EDFA case, demonstrating that a single decision logic applies across physically distinct failure modes.

Case study 4 — false alarm (trajectory 1215). OSNR decays slowly from 18.8 dB toward \(\sim\)15.2 dB but does not cross the 15 dB threshold within the 900-sample observation window; alarm nonetheless fires at \(t{=}894\). SHAP attribution shows the decision is driven by current OSNR and the rolling mean at marginal values—operator-interpretable reasoning that would likely resolve to a true positive had observation continued. Such marginal alerts illustrate the intended operational use of SHAP: support operator review and continuous learning.
Global feature importance
Aggregating SHAP values across 5000 real test samples produces a markedly different distribution from the synthetic-data analysis(Fig. 9). On real data, current OSNR contributes 77.9% of total mean-absolute SHAP, with SNR\(_{t-10}\) (6.9%), rolling mean (6.3%), and rolling standard deviation (5.1%) forming the next tier; velocity contributes 0.75% and acceleration 0.1%. This concentration reflects the smoother, less jittery character of real telemetry compared to stochastic-simulator trajectories (which inject controlled noise to differentiate failure modes).
Interpretation: at the aggregate level, current OSNR is the strongest single predictor. At alarm moments specifically (Sec. Per-Alarm Interpretability: Case Studies), rolling statistics contribute \(\sim\)25–30% of per-decision attribution. The derivative features remain informative for distinguishing among failure modes (as demonstrated in the cross-physics synthetic validation), but their contribution is concentrated at the decision boundary rather than uniformly across the operational envelope.

Global SHAP feature importance on 5,000 samples from the real Mendeley test set. Current OSNR contributes 77.9% of total mean-absolute SHAP; SNR\(_{t-10}\) (6.9%), rolling mean (6.3%), and rolling standard deviation (5.1%) form the next tier. Derivative features contribute 0.1–0.75% in aggregate, but the per-alarm case studies (Figs. 6–8) show their contribution rises to 20–30% at decision moments.
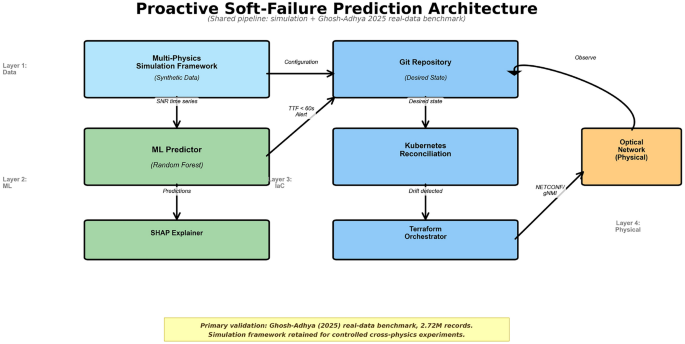
End-to-end latency budget
Table 4 reports stage-wise wall-clock latency of the proposed pipeline, measured over 200 iterations per stage. Stages 1–4 are directly measured; stages 5–6 are estimated from published Kubernetes controller benchmarks and Sgambelluri et al.’s16 reported Terraform-to-OpenROADM apply times, as we do not currently operate a physical optical device in the loop (Fig. 10).

End-to-end latency budget of the proposed pipeline (log scale). Error bars indicate 5th/95th percentiles across 200 iterations per stage. ML-pipeline contributions (stages 1–2, totaling \(\sim\)25 ms) are below the readable range on the log axis; orchestration stages (5–6) dominate the budget, identifying them as the primary optimization target for future work.
Three observations follow. First, ML inference is negligible: feature extraction plus RF inference totals 25.2 ms–less than 0.5% of the end-to-end budget. Physics-inspired tabular features plus tree inference yield a decision pipeline that is operationally invisible. Second, the persistence filter is the dominant deliberate delay, representing a design choice (two additional polls at 1 s intervals) that reduces the synthetic-data false-alarm rate from 12% to 2%. Third, orchestration stages (Kubernetes + Terraform) together account for 68% of the total budget. These stages are the legitimate optimization target for future work; options include pre-compiled Terraform plans, event-driven reconciliation instead of polling, and direct NETCONF APIs bypassing the Terraform layer for time-critical migrations.
The measured 6.7 s budget fits comfortably within the observed lead times from Sec. Per-Alarm Interpretability: Case Studies: 44 s for the EDFA case and 30 s for the NLI case. At the shortest NLI lead time, the pipeline consumes 22% of the available budget; at typical EDFA lead times, 15%. The orchestration layer is therefore fast enough to act within the prediction horizon for gradual failures. Although the real-data MAE of 73.2 s is larger than the simulation-only result (17.9 s), the shortest observed lead time (30 s for NLI failures) still exceeds the measured 6.7 s orchestration budget by 3.5\(\times\), providing adequate operational margin for make-before-break migration.